
Is it really fair or did you automate it?
Published:
The following article is an overview of my understanding of the Lesson 2: Bias & Fairness taught by Rachel Thomas. It also represents my notes for the course and is also an attempt at a blog post series to increase awareness about various concepts in fairness and ethics.
Fairness and Bias
Fairness has been talked about since a long time in the field of Computer Science or any other policy related fields where third party decisions influence the lives of other people. However, it has always been the case that fairness has always been described broadly as being impartial to people and in a real world scenario, such a vague definition wouldn’t yield much results. Bias is a term which is often used in juxtaposition with fairness. So it would be wise to understand bias first and then move on to fairness.
Applications & Biases
Starting off with some examples of bias which exist in products seems like a good idea and that’s what we’ll be doing!
Representation Bias in Facial Recognition
Gender and ethnicity have been the most talked about subjects when we consider algorithmic bias. Right from the existing gender bias in Google Translate to the infamous research regarding facial recognition technology by Joy Buolamwini and Timnit Gebru, gender and ethnicity have been at the forefront whenever the community has tried to deal with bias. So, in this section we’ll be discussing the facial recognition results and why it was a better approach than the other ones.
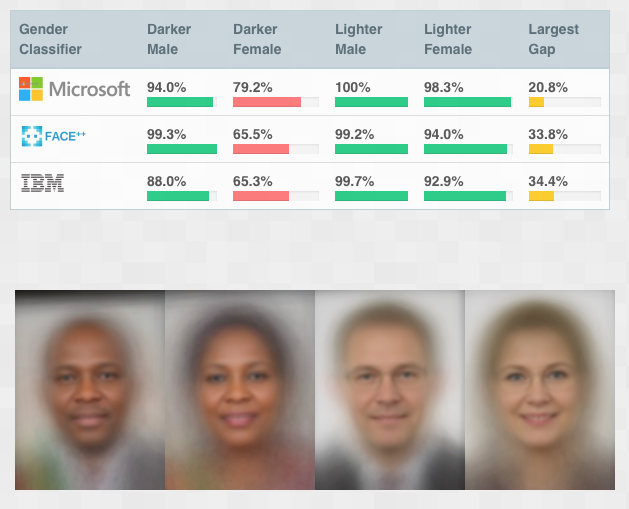
The research conducted across various facial recognition technologies could be considered sort of bi-directional as it considered both gender as well as ethnicity and looked at the real accuracies of them. As it can be observed in the figure, there were glaring gaps in how this model actually behaved on various categories and it is conspicuous that darker females achieved the worst accuracy which would mean that the bias was quite higher than realized and there are a lot of reasons for this algorithmic bias which we’ll be discussing further in detail.
The question isn’t just about removing bias but also identifying how the tech is used
Bias in Recidivism software
Recidivism means calculating the probability of a convicted criminal to reoffend. Since this has been an important problem while dealing with detention sentences and also to lower the crime rates, a lot of places came up with using computer software in order to predict the risk of an individual to commit further crime and then sentence them accordingly. However in a report published by ProPublica, a lot of biases started popping up. A seasoned white criminal being rated as low risk when a African-American child with just a misdemeanor in her record was labelled as high risk and put in jail was one of the many such “bizarre” incidences that the report sheds light on.
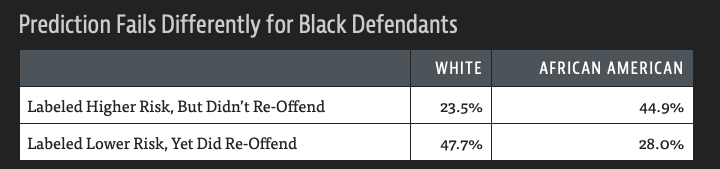
As mentioned in the report, “Overall Northpointe’s assessment tool correctly predicts recidivism 61 percent of the time. But blacks are almost twice as likely as whites to be labeled a higher risk but not actually re-offend. It makes the opposite mistake among whites: They are much more likely than blacks to be labeled lower risk but go on to commit other crimes.”
Upon further research it was also found that this “complicated” software was no better at predicting reoffense risk than a linear classifier with 3 variables. This is very serious as it could invalidate a lot of sentences issued using the same software. The most interesting thing in this case was that while evaluating every case, ‘race’ was never an input into the software. This would mean that even in the presence of sensitive data, machine learning excels at finding latent variables and deriving the said bias from those variables. We’ll also discuss a thought experiment about this later!
Predictive Policing
Predictive policing is a process in which police are allocated all over the city in such a way that the crime rate is minimized. In principle, this should be an optimisation problem. However, it resulted in being much more than that. As discussed by (D. Ensign et al.), predictive policing software gives rise to a number of issues.
Since, it has to be trained on previous incidents data, there is a chance of inducing historical bias. This would mean that the model would also learn the exploitation of certain communities and assign more police officers in that area, just based on the historical record data. This causes the rise of feedback loops. This means that in case of predictive policing, the next round of data that you’re going to receive for re-training is controlled by the model itself. This can be understood easily by an analogy to the Stanford Prison Experiment. Just like the experiment, officers deployed in exploited areas might cause psychological distress to the people living there and thus, increase the chances of a crime occurring in that region. Thus, this doesn’t help curb the crime rate at all and instead introduces new factors to influence the crime rate.
This predictive policing failure could be concisely summarized by a quote from Suresh Venkatasubramanian :
“Predictive Policing is aptly named: it is predicting future policing, not future crime”
Different sources of bias and their causes
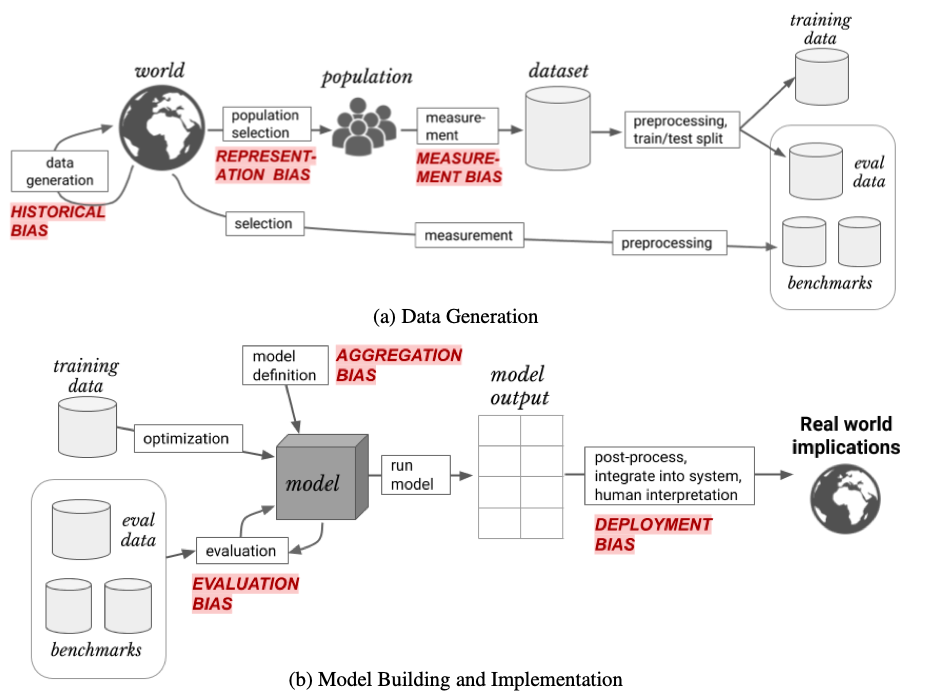
As proposed by (Harini Suresh and John Guttag, 2019), the whole KDD process (or a pipeline) of any Machine Learning process leads to various different kinds of biases at different stages which can be observed in the diagram and so now, we’ll have a look at each of them separately and how they occur.
Histrorical Bias: This occurs in the data generation process. It occurs when the data being collected represents a version of the world which is significantly different from the society in which it is to be deployed. This data assumes that right from the time of the data being generated, there have been no changes in the world, which might be true in an ideal scenario, however, that’s not the case in the real word and this could cause a lot of problems.
Representation Bias: This is often created during the data selection part. As observed in the facial recognition software, the data under-represents and even fails to generalize over any sub-group of population which is going to use the software.
Measurement Bias: This occurs during the feature selection phase. This bias generally happens when the selected features may leave out crucial data and thus, create a situation where these selected features then act as the latent variables to create bias as observed in the recidivism software.
Aggregation Bias: This occurs when various models trained on separate populations are aggregated to form as a whole. This is probably done in order to solve the problem that ‘one model cannot handle such heterogenous population’. However, aggregation leads to distinct population being inappropriately combined.
Evaluation Bias: This evidently occurs during the evaluation phase when the evaluation sets do not represent the entire population. This leads to no detection of any existing bias and the subgroup present heavily in the evaluation set is what the model then optimizes on and is biased towards that same model. This is also the reason why Kaggle has separate ‘public’ and ‘private’ leaderboards in order to check if the model is really good or is it just overfit on the eval data.
Deployment Bias: This could be a completely human induced bias (even though every bias is indirectly a human induced bias). This occurs when the system is used in such a way that the results are misinterpreted and thus, cause more harm than they help the others.
Case Studies on Specific Biases
Before diving into different case studies about bias, I’d like to highlight a question which was asked during the lecture. The person asked that while discussing biases, we often highlight physical constructs such as race and gender upon which these biases occur. However, are there any other kinds of biases which aren’t as apparent as these constructs?
The answer to this was very interesting and also unclear at the same time. Since, these softwares are built using models which are considered to be a ‘black-box’ to a certain point, no one can surely point out what bias is being settled into the model actually. However, there could be a case that the models learn social constructs such as language, country of origin,etc. and are partial towards these. Even though, these aren’t taken into consideration during deployment, but there could be a case where these factors act as latent factors and insert an undetectable bias. It is also interesting that all of these supposed “attributes” are socially constructed. This means that if you consider historical data, white people from a certain country wouldn’t have been considered white 200 years ago and thus, historic bias along with the origin country would act up and create bias in this case. This is why dealing with bias is considered to be a very complicated task. A possible solution to this problem is to talk to domain experts for which the solution is being built, as much as one can.
Along with this, there were suggestions to reconsider the term ‘tech industry’. This was well presented in the blog post by Anil Dash. He suggests that the industry has become too big to consider it just as a community of software engineers and thus, help with proper policy making for the same.The need for the same was also observed in many cases such as the Amazon incident. Proper monitoring and policy making can prevent such fiascos.
1. Machine Learning and Moral Hazard
This case study is an overview of the research study conducted by Sendhil Mullainathan and Ziad Obermeyer. In this research study, the authors tried to find out the leading factors which could predict the possibility of stroke in a patient. To conduct this study, they used historical EHR (Electronic Health Record) data of patients.
At the end of the research, they found out and listed the various factors which were figured out in the process. The top 2 factors responsible to predict a stroke were ‘Prior Stroke’ and ‘Cardiovascular Disease’. These factors made a lot of sense intuitively as these are also the factors the doctors generally ask the patients for. However,upon listing further, there occurred some abnormalities in the factors.
The next 4 important factors after these 2 were ‘Accidental Injury’, ‘Benign Breast Lump’, ‘Colonoscopy’ and ‘Sinusitis’. It doesn’t take a medical expert to figure out that these factors aren’t correlated much to having a stroke. Then why did the model mention these factors among the most important? Upon conducting further analysis of the data, the authors found that in the actual experiment, they didn’t measure the probability of having a stroke. What they instead measured was ‘have symptoms, go to doctor, get tests, AND receive diagnosis of stroke’. This was a classic case of Measurement Bias. This also led to an important corollary that simply quantifying how well algorithms predict ‘y’ is not enough to gauge the quality of the said algorithms.
2. Aggregation Bias on Healthcare
It has been proven by (Spanakis and Golden,2013) that diabetes patients have different complications across various ethnicities. It has also been observed in (Herman and Cohen, 2012) that the HbA1c (which are used to monitor diabetes) differ in complex ways across various ethnicities and gender. Thus, taking these cases in mind, it would probably seem that a universal model wouldn’t be a smart way to eliminate bias completely as aggregation bias would distort the results across ethnicities and thus, defeat the whole meaning of building the product altogether.
Alright, I still don’t understand why Algorithmic Bias matters?
It’s not just the data! Machine learning can amplify bias. As proposed by (De-Arteaga et al.,2019),it was observed that the algorithms were clearly amplifying bias in an already biased dataset. For example, the proportion of females in an occupation dataset who were surgeons was 14.6%. This was already very bad. However, on trying to predict the occupations using the model, it was found out that the true positive rate was 11.6%. This clearly shows that the model detected the bias in the data and amplified it further. Thus, this is another example of why algorithmic bias should be an important factor to us.
Other than this, algorithms are used very differently than human decision makers. It has generally been the case that people assume that the algorithms in place are objective or error-free. Thus, even if an option is provided for human override, they don’t utilise it. Along with this, most of the times, algorithms replace people as cost-cutting measures. Thus, due to this no appeals process is in place to challenge the decision of these algorithms as it would require extensive manpower. Thus, this results in worsening of the situation further. These algorithms are also used at scale. However, they aren’t necessarily designed/trained with data which represents the real world population and thus, aren’t able to function properly at scale with the existing diversities. Along with this, the algorithmic systems are cheap as they’re meant to replace the human workforce. Thus, utilising high-quality datasets and good fairness practices is out of question at such times. A great quote by Cathy O’Neil in her book Weapons of Math Destruction summarizes this as:
“The privileged are processed by people, the poor are processed by algorithms”
Humans are biased, why does algorithmic bias matter?
As we observed earlier, algorithmic bias matters so much because it can create feedback loops (such as the one in predictive policing). Along with this, Machine Learning can amplify that existing bias. In the real world, even though it may seem similar but humans and algorithms are utilised completely differently. Since, technology grants additional power to human beings, an additional responsibility also comes with it.
On observing more intricately, we find that computers do exactly what we tell them to do. Even in Machine Learning, we define what success is. This success is generally achieved in the form of minimizing an error function. But who gets to decide that error function? Isn’t it completely subjective?
For example, when someone gets tested for Cancer, which would be considered worse? A false Positive or a false negative? The right answer in this case might be a false positive, since the person can get further tests done and find out that they don’t actually have cancer. However, the situation might be much worse if your model gives out improper false negatives. (This also depends, if you keep on predicting positive for every case you get, then the model should probably be thrown out.)
Conversely, if you think about your email inbox spam classifier. Which would be considered worse? A false positive or a false Negative? a false Positive here would signify that an email which wasn’t spam got classified as spam and was sent to the spam folder. This could be a crucial email. On the other hand, a false negative just puts an unnecessary email in your primary folder and thus, this doesn’t cause as much harm as the other one. (Again, depends on the proportion.)
Considering both these examples and the complexity of all existing systems, how can it be expected to just get optimum results by minimizing an error function which is completely context depdendent? And how would one even go about automating that process too?
If the above two examples seem really simple, let’s consider a thought experiment of a similar ‘Which is worse’ scenario on our criminal recidivism system. Which would be worse in that case?
A false positive would denote that a person who is not likely to reoffend would be sent to jail and thus, their chance to rebuild and correct their mistakes gets taken away. A false Negative means potentially putting a criminal on the street.
How would one even decide what to optimize in such cases?
Is introducing fairness really that difficult?
Before going into this, a very good point was discussed. A student questioned that if no safeguards are set to ensure fairness, wouldn’t this wreak havoc in the whole system? However, similarly, if we have a system of receiving 100% accurate data, wouldn’t this prevent the underprivileged from getting access to healthcare and other such necessities?
CarCorp Conundrum
This case study was mentioned by (Passi and Barocas,2019) and is really good example of the whole data science process and how fairness would fit into that. In this case study, a 6 month ethnographic field study was conducted which included the involvement of a lot of data scientists, business analysts, product managers as well as executives. The case study revolves around a company called CarCorp which collects special financing data of people who need auto loans but have bad credit scores (300-600) or even limited credit scores. The company then sells this data to auto dealers, who use this data as a leads generation directory. Now, the company (CarCorp) wanted to improve the quality of leads that they were providing and thus, announced this ethnographic study.
Initially, they pondered upon the basic questions such as ‘What makes a lead high quality?’. The possible factors to this were the buyer’s salary, whether the car the buyer wanted was in stock at the dealer’s showroom and how did the buyer plan on financing the vehicle along with if the dealer supported that process of financing.
However, the roadblock in building such quality of leads was that dealers didn’t want to share financing data. Along with this, the company found that the credit scores were segmented into various ranges such as 476-525, 526-575, etc. This resulted in the resources being diverted to predicting the credit score as the company estimated that this would be the ideal indicator of quality and thus, the problem was reduced to predicting if a particular client had a credit score above or below 500.In addition to this, the company also considered using high quality datasets with extremely accurate values. However, these datasets were very expensive and not really affordable for operations. Due to this, the whole project failed.
As we observe here, the whole problem started with a good approach to the solution, but in the end got reduced to a basic classification problem and thus, the thought of considering fairness went out of the window (since credit scores aren’t really the epitome of unbiased indicators).
On discussing during the lecture, what could’ve done to consider bias and fairness in this scenario, a lot of good solutions were proposed. One of them answered that the ‘quality’ in itself was a subjective metric. The first important thing that they should’ve done would be to ensure that the definition of quality is in alignment among all the people involved. If that’s not the case then using machine learning to predict quality just becomes another example of what Pinboard creator Maciej Cegłowski had proposed i.e. Machine Learning is just money laundering for bias
The other solution was that the business model should’ve been changed to how to sell more cars to more people. For doing this, instead of using opaque, biased systems like credit scores, the company could’ve looked for customers. The basic question to ask here was “Do you have $x in down payment and can you afford $y per month?”.
What are the solutions to these problems?
In order to solve various biases and ensure fairness at all points in a pipeline process of the product, the following questions must be asked about the AI:
Should we even be doing this?
As an engineer, the first thought that comes to my mind whenever I see a problem is “What can we build to fix this?” However, sometimes the answer to this question would be NOTHING. This was the concept which was also proposed by (Baumer and Silberman, 2011). Sometimes trying to solve some problems leads to other problems such as the one mentioned by (Wang et al., 2019) where facial features could be used to detect ethnicity of the person. Some of these “solutions” could be a double ended sword i.e. it could be bad if they’re wrong and even worse if they’re right and one such example of those would be this.What bias is in the data?
This is an important question to identify as well as solve. As discussed extensively before, identifying bias in the data is a crucial step to building a product.Can the code and data be audited?
Building upon her undergrad specialization as an electronic engineer, (Timnit Gebru et al.,2020) proposed a system to maintain kind of a datasheet for the data being used in a product. This datasheet would look like a part description sheet of an electric component where every aspect of the data being used is extensively stated. It would include questions such as Who was involved in the data collection process (e.g., students, crowdworkers, contractors) and how were they compensated (e.g., how much were crowdworkers paid)? This kind of an open auditing mechanism would also help in identifying biases in the data. The prototype for the same datasheet can be found here. Along with this, the auditing of code is important to prevent various other measurement and aggregation biases.What are the error rates for different sub-groups?
As observed in the facial recognition example and evaluation bias, we find out that this is quite important. Thus, correct error rates for every sub-group need to be kept on track.What is the accuracy of a simple rule-based alternative?
As observed during the criminal recidivism example, the complicated model had lesser accuracy than a simple linear classifier. So, it would also be wise to look at simple rule-based alternatives in order to keep it simple. It is as the quote says: Don’t use BERT when regex can do the job!.What processes are in place to handle appeals or mistakes?
An appeal system is necessary to deal with errors happening in the automated product. Appeals system could also work for a lot of systems such as the ones with completely automated ones which cannot handle clerical errors. At such times, human contact is often craved and even necessary to deal with these errors taking place and also finding out the gaps in the system.How diverse is the team that built it?
Team diversity is a significant aspect when deciding on product building as biases can only be eliminated if the people building the product understand the issues. These issues can be uncovered often in case of diverse teams and extensive testing of the product among these people.
This is the end of my article. This is the first time that I’ve written about bias and fairness and so if you feel I’ve offended you in some way or have made a mistake which needs to be corrected, please feel free to reach out. Thanks for reading, hope you liked it!